LaTeX 中暂存答案
本文介绍如何在 LaTeX2e 中实现答案控制的效果,也即是答案统一在后面显示,考虑到有些朋友没有学习 LaTeX3,所以本文尽量用 LaTeX2e & TeX 来实现,如果对 LaTeX3 感兴趣,可以参考下面的文章
实现原理
我们的想法其实就是要在前面输入答案,但是不做输出,而是存起来,然后放到指定位置输出,例如
1 | 1.这是题目这是题目... |
大概就是这样,使用 \showanswer 命令来显示答案
讨论
不知道大家有没有注意过一个问题,在标准文档类中的 \author,\title,\date , 这些命令使用后并不会立即输出,而是等到 \maketitle 命令的到来才会输出,其实它就在做这样一个事情
为了更加清楚,我们来看看其源码,在命令行使用 latexdef -s \author 即可查看其定义

哎,简化一下吧,大概类似于
1 | \newcommand*{\author}[1]{\newcommand{\@author}{#1}} |
嘿,我们再来看看 \maketitle 命令呢,同样使用 latexdef -c article \maketitle

好吧,有点乱,我也没读懂,我猜测应该是设置了一些格式,然后将前面定义的所有与封面相关的元素全部删除了,好像没有多少对我们有用的信息呢. 咿,我发现有个 ,\@maketitle ,这小家伙藏得还挺深,还是被我揪出来了latexdef -c article \@maketitle
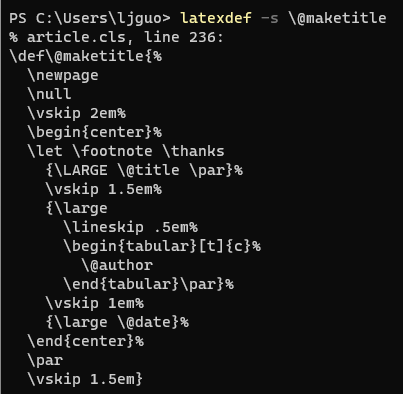
原来都藏在这儿呢,在封面使用前面定义的 \@author \@title 等,注意了,不是 \author \title 哦.
(做封面的朋友该有想法了)
回来吧,现在我们应该清楚了,\author 命令的作用只是在间接定义 \@author ,实际并不做输出
开始动手
设计输入
我们也可以仿照它的做法,来实现我们的效果,使用如下代码
1 | \newcommand{\answer}[1]{\def\@answer{#1}} |
这里使用 \def 是为了避免 Command \@answer already defined. 的问题
但是这样有一个问题,当我们使用
1 | \answer{A} |
后,实际保存在 \@answer 里面的值是 C,所以我们只用一个宏来保存答案似乎不太好办(LaTeX3 里面倒是很简单),最好是为每一个题目都分配一个宏来保存答案,考虑如下
1 | \newcommand{\answerI}[1]{\def\@answerI{#1}} |
一张试卷 20 多个题目,难道我们要定义 20 多个命令?太麻烦了!如果能自动根据题号来定义命令就好了
唉,我想到了计数器,为其分配一个计数器 answer,尝试如下代码
1 | \newcommand{\answer}[1]{\def\answer\theanswer{#1}} |
这样,使用第一次 \answer 就定义了 \answer1 , 第二次就定义了 \answer2 ,但是这样定义有两个问题
\def\answer\theanswer本身是有问题的\answer1这样的命令命名是有问题的,数字正常情况下不能作为命令名
但是,不要气馁,我们正在慢慢接近答案
解决第一个问题就涉及到 TeX 中 迷人的宏展开 了,当然这里只涉及到很简单的
介绍两个命令 \csname 和 \endcsname , 我们使用如下命令
1 | \csname textbf \endcsname{abc} % ---> \textbf{abc} |
也就是说,夹在 \csname 和 \endcsname 之间的部分会先被完全展开至不可展开为止,然后再为其加上 \ 使其成为一个控制序列(命令)
解决第二个问题也很简单,我们只需将数字转化为罗马数字即可,这里是计数器,我们直接使用现成的\roman{answer} 即可
我们考虑如下定义
1 | \def\answer#1 |
这里使用了 \expandafter ,是为了跳过 \def 先展开 \csname 和 \endcsname 之间的内容,然后再 \def
设计输出
输出的话我们可以
1 | \answeri |
但更好的是使用循环来做这件事情,这里使用 pgffor 宏包提供的 \foreach 命令
1 | \foreach[parse] \x in{1,2,...,\theanswer} |
注意这里的 \romannumeral 接受一个数字, 并将其转化为小写罗马数字,区别于刚刚的 \roman , 它是接受一个计数器,而不是接受数字
实现源码
现在我们将代码整合一下
1 | \documentclass{ctexart} |
输出

好了,至此本文结束,下期再见吧 ~